Interpretability vs Neuroscience
Posted on March 12th, 2021
I study what goes on inside artificial neural networks. I don’t know anything much about actual neuroscience, but I'm sometimes struck by how much easier my job is than a neuroscientist's.
This essay lists advantages that make it easier to understand artificial neural networks. If we're to make rapid progress on understanding artificial neural networks — when countless brilliant neuroscientists have only started to understand the human brain after decades of research — we should probably be trying to exploit these advantages as ruthlessly as possible.
Advantage 1
You can get the responses of all neurons for arbitrarily many stimuli.
In neuroscience, one is limited in the number of neurons they can record from, their ability to select the neurons they record, and the number of stimuli they can record responses to. For artificial neural networks, we can record the responses of all neurons to arbitrarily many stimuli. For example, it’s not unusual to use recordings of how every single neuron in a network responds to millions of natural stimuli.
There's no lab work involved. Turn arounds are much faster than biological experiments (essentially instant for small scale recording). There's no recording noise. No synaptic fatigue. And if you don't get the recordings you need the first time, you can go back and record again from the exact same neurons, which haven't changed at all.
Advantage 2
Not only do you have the connectome, you have the weights!
A major undertaking in neuroscience is the attempt to access the connectome — the graph of how neurons in a brain connect. Even if they succeed, they won’t know the weights of those connections. Are they excitatory or inhibitory? How strongly excitatory or inhibitory are they?
With artificial neural networks, all the connections and weights are simply there for us to look at. And since we also know how these artificial neurons are computed, in principle we have everything we need to just reason through and understand the neural network.
This is tricky, but if you’re willing to look you can literally read algorithms directly off
the weights of the network. This is one of the main ideas behind circuits.
Advantage 3
Weight-tying massively reduces the number of unique neurons!
Artificial neural networks often leverage a technique called weight-tying, in which we force many neurons to have the same weights. The most common use of this is in convolutional neural networks, where each neuron has translated copies of itself with the same weights. (If you're unfamiliar, see my tutorial on conv nets and weight tying.)
The effect of weight-tying on interpretability is really under-appreciated. For example, in ImageNet conv nets, weight-tying often reduces the number of unique neurons in early vision by 10,000x or even more! This results in artificial neural networks having many fewer neurons for early vision than their biological counterparts. For example, V1 in Human vision is about 150,000,000 neurons, early vision in InceptionV1 (very expansively defined) is only about 1,000 neurons. This means we can just literally study every single neuron.
Advantage 4
Establishing causality by optimizing the input (feature visualization)
In my experience, one of the thorniest issues in understanding neurons in artificial networks is separating correlation from causation. Does a neuron detect a dog head? Or does it just detect part of a dog head? Perhaps it just detects an ear, or an eye, or fur parting in a specific way. Perhaps it detects something that has no intrinsic relationship to dog heads, but is really correlated with their presence. Framing this issue as "correlation vs causation", while true, perhaps understates the problem. There's a second very closely related problem: we don't know what the space of likely functions a neuron might perform is. So we can't just pin down a couple hypotheses and devise an experiment to separate them.
I imagine this is also a challenge in neuroscience.
Artificial neural networks offer us an immensely useful tool for solving this which we often call feature visualization. We create stimuli “from scratch” to strongly activate neurons (or combinations of neurons) in artificial neural networks, by starting with random noise and optimizing the input. The key property of feature visualization is that anything in the resulting visualization there because it caused the neuron to fire more. If feature visualization gives you a fully formed dog head with eyes and ears arranged appropriately, it must be detecting an entire dog head. If it just gives an eye, it's probably only (or at least primarily) responding to that. If it was detecting a watermark or something in the background, feature visualization would render that. (There's an important caveat about the regularization of feature visualizations; see discussion in the section of our tutorial titled "The Spectrum of Regularization".)
Optimizing inputs is also how adversarial examples were discovered!
Recent efforts in neuroscience have tried to develop similar methods [], by using an artificial neural network as a proxy for a biological one. This work is very interesting, but it’s unclear they give you the same ability to establish a causal link. It seems hard to exclude the possibility that the resulting stimulus might have content which causes the artificial neurons predicting the biological neuron to fire more, but aren't causally necessary for the biological neuron to fire.
Advantage 5
Interventions, Ablations, and Edits
Optogenetics has been a major methodological advance for neuroscience in allowing neuroscientists to temporarily ablate neurons, or to force them to activate. This is a powerful tool for interrogating neural circuits and establishing causality.
Artificial neural networks are trivial to manipulate at the level of neurons. One can easily ablate neurons or set them to particular activations. But one can also do more powerful "circuit editing" where one modifies parameters at a finer grained level.
This is still early days, but we've already seen interesting examples. In image generation, Bau et al., 2018 show that you can ablate neurons to remove objects like tress and windows from generated images. In RL, Hilton et al., 2020 show that you can ablate features to blind an agent to a particular enemy while leaving other competencies in tact. More recently, Cammarata et al, 2021 reimplements a large chunk of neural network from scratch, and then splices it into a model.
Advantage 6
We can study the exact same model.
Neuroscientists might study a model organism species, but each brain they study has different neurons. If one neuroscientist reports on an interesting neuron they found, other neuroscientists can't directly study that same neuron. In fact, the neuroscientists studying the original neuron will quickly lose access to it: probes can't be left in indefinitely, organisms die, human subjects leave, and even setting that aside neurons change over time.
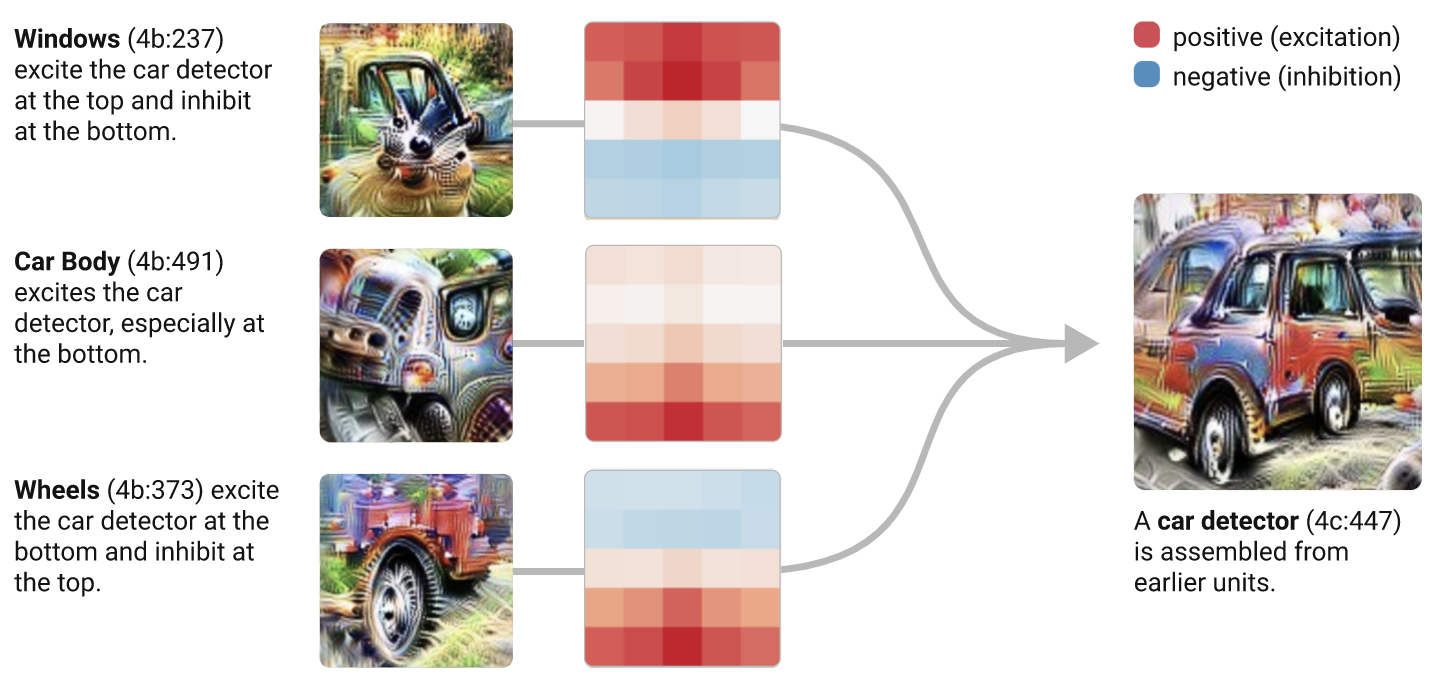
Studying artificial networks, we can collaboratively reverse engineer the same “brain", building on each other. My collaborators and I all know that in "canonical InceptionV1", 4c:447 is a car detector. In fact, when a colleague at another institution makes neural network and posts it on twitter, I can recognize by eye the neurons he used. This is entertaining, but reflects something which I think is quite remarkable: we have a shared web of thousands of "footholds" into InceptionV1, consisting of neurons we understand fairly well and know the connections between, which makes it massively easier to explore.
BonusReduced Moral Murkiness
I care intensely about the welfare of animals. I'm willing to accept that the suffering of animals can be outweighed by the benefit of the research. But I feel very fortunate to not need to make that call -- to wonder if, for each experiment, the benefit is sufficient to justify the suffering. (Although I do think it's worth thinking quite critically about whether there is a point where we need to start extending moral patienthood to artificial neural networks.)
I realize the above may seem sanctimonious to those who don't share my values. At a more pragmatic level, artificial neural networks mean you don't need to work with IRBs.